
In this blog, we will outline some of the key points in the Apache Pinot Annual Recap and Roadmap Discussion. To view the full discussion on YouTube click here or the video below!
Community Updates & Growth
Presenter: Kishore Gopalakrishna, CEO at StarTree and Apache Pinot Co-Author
One of the biggest news of 2021 is the graduation of Apache Pinot in the Apache Software Foundation (ASF). ASF has a high barrier to entry for a project to graduate from incubation to a top-level project. This was not possible without all the awesome people who contributed for the last four or five years.

Apache Pinot Graduation – Art by Neha Pawar, Apache Pinot PMC
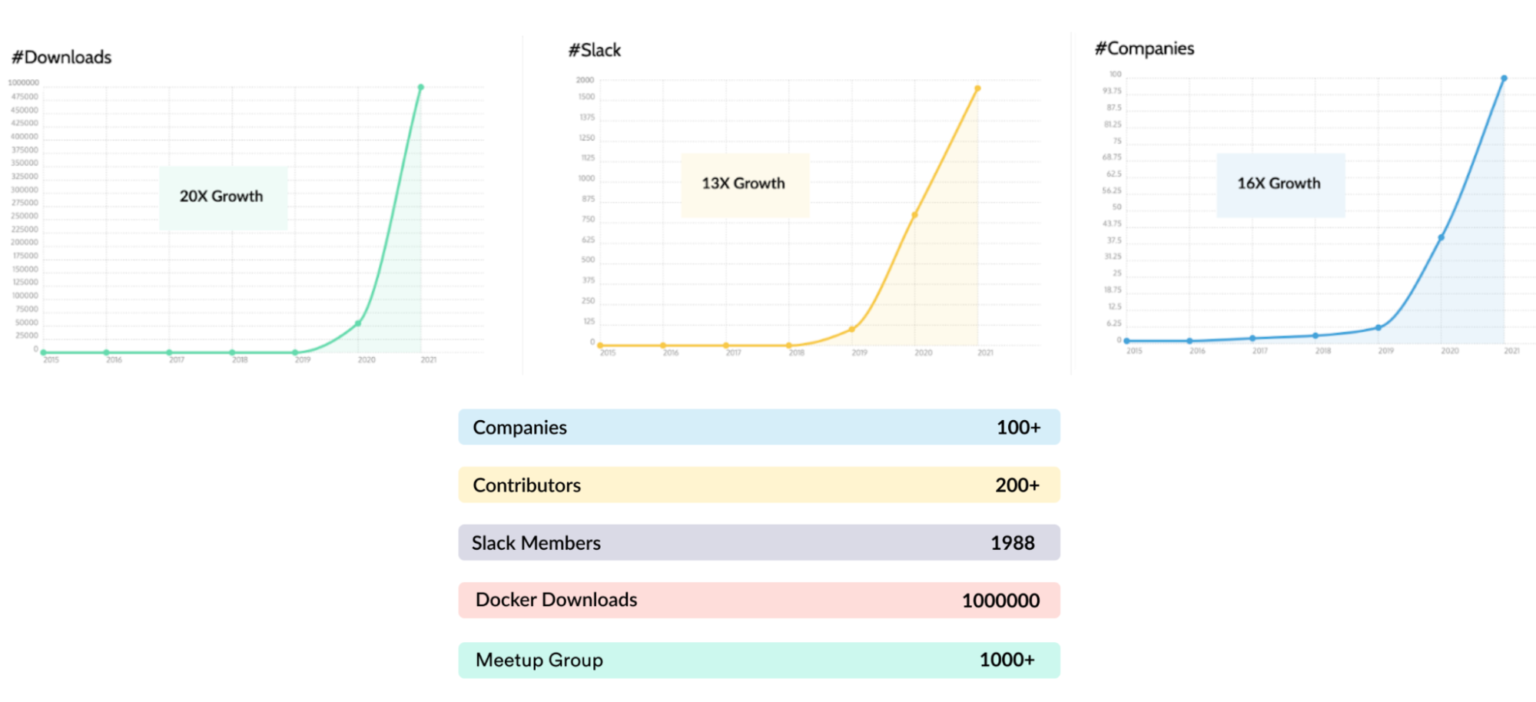
The project started way back at LinkedIn in the 2015-2016 timeframe. But in the last two to three years the community growth has taken off and the project has achieved a lot of big milestones. Earlier this year, we had 50,000 downloads, and yesterday, the project reached 1 million downloads! We are close to 2000 members in the slack community and double the contributors from this time last year.
Adoption Growth
Kishore Gopalakrishna
There are a lot of great companies with very, very high scale adopting Pinot, taking it up as one of the most critical pieces for their infrastructure; being able to provide analytics both to their internal users and also their external customers as well.

Apache Pinot Scale at LinkedIn
If you’re using LinkedIn, you are accessing Pinot in some shape or form. Any number that you see on LinkedIn whether you go “Who Viewed My Profile?” or your LinkedIn feed, you are querying Pinot behind the scenes. The numbers are very impressive here, with 100K+ queries per second, 1 million+ ingestion rate, and 20B+ records per second.

Apache Pinot Scale at Uber
Many different systems in Uber are now powered by Apache Pinot. If you open an Uber Eats app today, and if you see orders near you, you are making a query to Pinot. 800 million per second, 1.6 GBS, and 30K queries per second are impressive numbers.

Apache Pinot Scale at Stripe
Stripe started using Pinot last year, but their scale has been enormous. And it’s almost on the verge of overtaking, both LinkedIn and Uber on some of these scale numbers. It’s really big. They already have like 1PB + data size committing to 1 trillion rows. Almost every transaction in Stripe is getting stored in Pinot, and they’re able to achieve a sub-second latency on this, at this scale.

2021 Product Accomplishments
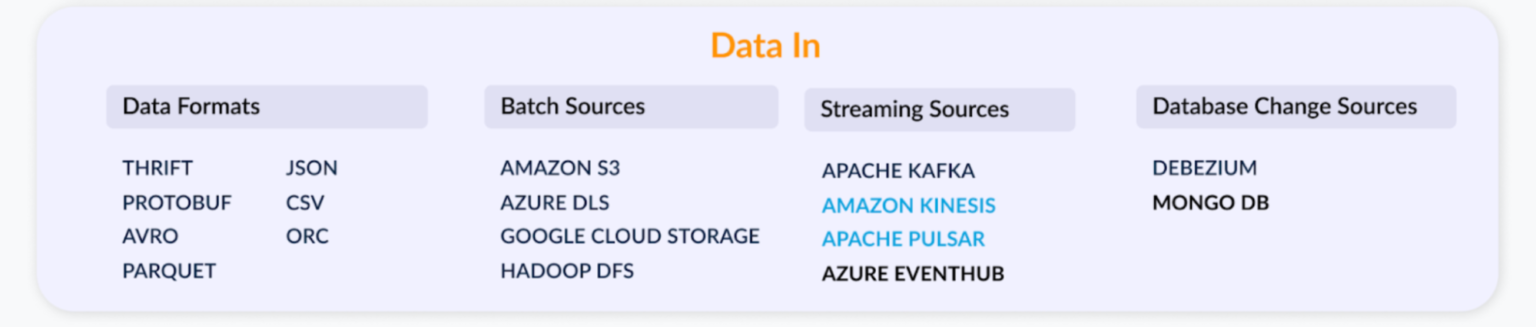
At a very high level, Apache Pinot is a system to ingest data from other sources, and much of what we focus on is how to make the ingestion easy and what are all the different formats that we want to support. We added a lot of new data formats, Thrift, Protobuf, Avro, Parquet, JSON, CSV, ORC, many more to come! The pluggable architecture of Pinot helps us to add all these new formats very quickly. HDFS was one of the sources that we used at LinkedIn, but now we have support for S3, Azure, and DCS as well.
Data In Updates
Streaming sources, such as Kafka, was one of the first sources that was supported. In terms of pluggability, we were able to add Kinesis and Pulsar. PubSub and Eventhub are something we are working on. Most of the time analytical systems catered only to append only use-cases where the records data doesn’t change, but thanks to Uber, we have the upsert capability in Pinot now, which means you can mutate the data on a record level basis, not at a segment level or daily level, so each record can be updated. This has opened up a lot of use cases for Pinot; you can simply point at a database via Debezium connector, start getting the data into Pinot, and then start querying it immediately. We continue to invest heavily in increasing the coverage here on different ingestion sources.
Indexing, Storage, and Query Updates
One of the secret sauces behind Pinot’s speed is indexing. We have added a lot of different types of indexing over the last year. We had the Lucene index, and are working to replace that with the native text index, which is showing a lot of performance improvement, overall, and in memory consumption. We also improved upon the range index and saw some significant performance improvements. The geospatial indexing allows you to ingest the geolocation data (based on lat / long), you can do very cool queries, such as, how many orders are near a particular zip code.
On the storage side, we added Upsert last year, and tiered storage ability to support nested data structures/complex data types, and also improve the compression on the storage side. We added the support for segment merging and roll up; this is a background task that continuously runs behind the scenes, organizing the segments daily, adding more indexes, or optimizing the segment format. There are a lot of performance boosts that come with this. Behind the scenes, it is based on the minion framework.
On the query layer, we are slowly moving from the single table query to multi tables. Look-up join is the first step in that direction. Now, you can do look-up joins with dimension tables that support a lot of different types of use cases so that you don’t have to denormalize everything.
We are also moving more towards the standard SQL, replacing some of the features where we had UDFs to support things like LightUp, LIKE, and other features directly in Pinot. The typical philosophy for us is to start with the UDF before changing, making the default change as to how this SQL standard behaves. We have added a lot of features here, JSON, Time, Groovy. Be careful when you’re using Groovy, with the recent log4J security is important, make sure you know what you’re doing with that feature. I would suggest turning it off if you don’t need that feature, although it’s very useful because it helps in terms of just writing your own custom function without having to understand Pinot’s internal details. And once you get the functionality, then you end up going and writing your own UDF.

Apps Updates
One of the reasons Pinot has become very popular is because of its ability to provide functionalities to your end users, which is typically done via apps. These are user-facing applications, such as Third Eye, which is anomaly detection, RCA, internal BI, and a lot of personalization log analytics.
We also understand that there are a lot of other ways of accessing this data using Presto, Trino, Superset, and other JDBC connectors. So these are all the visualization apps. And again, Presto, Trino also provides some of the missing functionality in Pinot, which is like joints. And it also helps you to join data from Apache Pinot to MyQ or Postgres or any other system. We continue to invest heavily in all these connectors, both on the inbound connectors, where we get the data into Pinot, and also the outbound connectors where other apps can consume this.

JSON Enhancements, Derived Column, Timestamp and Boolean Data Type, Query Thread Quota
Presenter: Jackie Jiang, Apache Pinot PMC and Committer
JSON Index Enhancement
- Support mutable JSON Index: Back in 2020, we introduced the JSON index, which can accelerate the filtering on JSON objects. In 2021, we added the mutable JSON index which can be used in real-time consuming segments. That fills the performance gap of filtering on JSON objects between consuming segments and sealed segments.
- Support JsonPath syntax: As shown in the query, we adopted the JsonPath syntax in JSON_MATCH predicate, which is used when querying the JSON Index. With this syntax, we can support filtering on any JSON object types including array and value. SELECT … WHERE JSON_MATCH(person, ‘”$.addresses[*].country” = “us”‘)
- Support indexing nested JSON array: We added the support of indexing arbitrary nested JSON objects, including multidimensional JSON array. Here is a query example querying a two-dimensional array. SELECT … WHERE JSON_MATCH(data, ‘”$.arrays[*][0]” = 15’)
Watch https://www.youtube.com/watch?v=TQoXSoKHLp8
JSON Index documentation https://docs.pinot.apache.org/basics/indexing/json-index
Derived Column:
- Derived column is the column derived from other columns via the ingestion transforms.
- We added the support of generating the derived columns during segment load so that derived columns can be added on-the-fly without re-indexing the entire dataset.
- With this, users can add pre-materialized columns to improve the query performance without backfilling the data:SELECT COUNT(*) FROM table GROUP BY toEpochHours(millisSinceEpoch) →Add ingestion transform: hoursSinceEpoch = toEpochHours(millisSinceEpoch)
SELECT COUNT(*) FROM table GROUP BY hoursSinceEpoch
TIMESTAMP and BOOLEAN Data Type
- TIMESTAMP and BOOLEAN data type are supported natively.SELECT … WHERE timestamp < ‘2021-12-02 10:00:00’
SELECT … WHERE isDelayed = true
Query Thread Quota
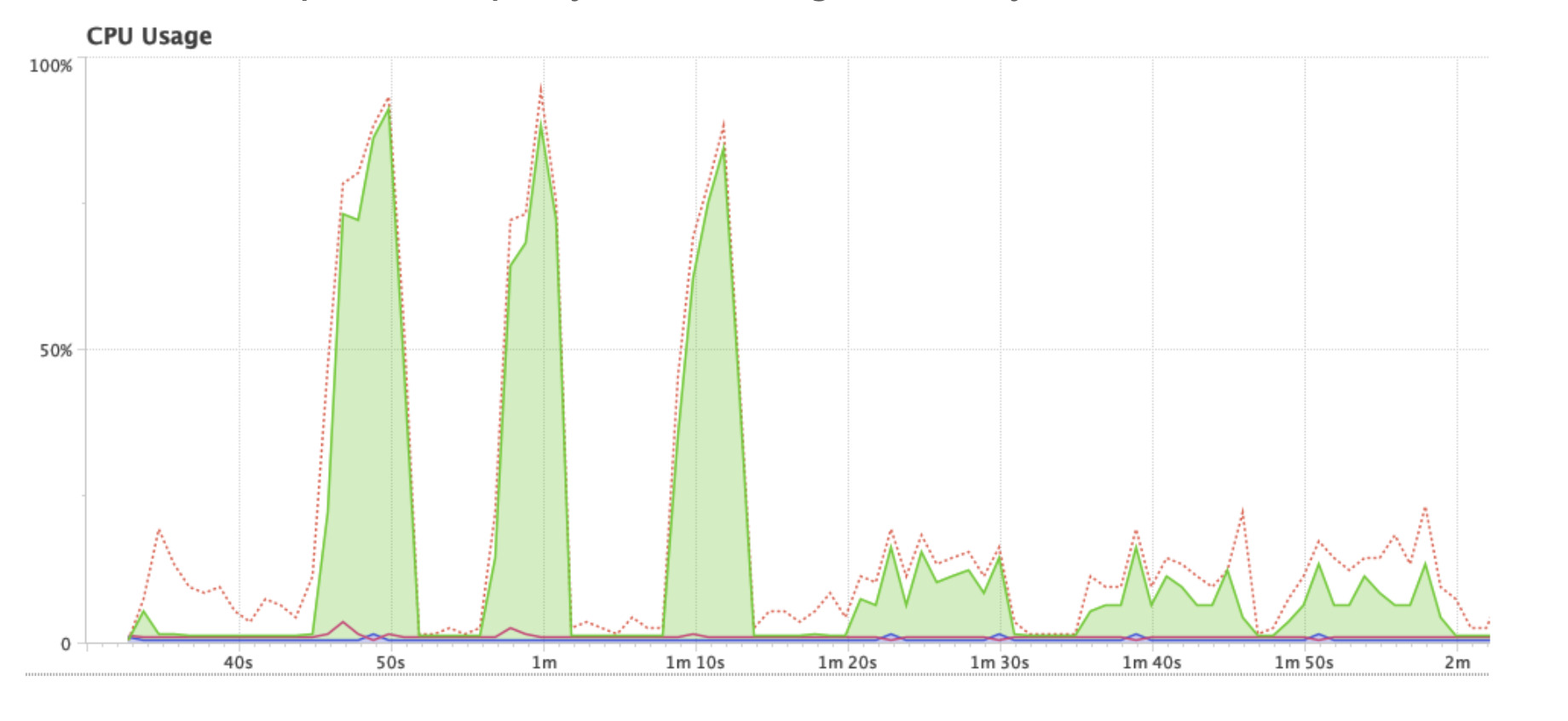
Allow configuring the maximum number of threads used for a query on the server to prevent one expensive query from exhausting all the system resources. In the graph, the first 3 queries do not have thread limit, and the following 3 queries have thread limit. We can see the first 3 queries used almost 100% of the CPU, but once we enable this quota, the CPU usage drops to about 20%.
V2 Range Index, V4 Raw, LZ4 Default Compression, Performance Improvements
Presenter: Richard Startin, Software Engineer @ StarTree
V2 Range Index:
The index with the best space-time tradeoff in Pinot is the sorted index, but it’s only possible to sort by one column. The sorted column would often be time, but having a reasonable range index frees up the sorted column for some other attribute than time, without sacrificing query latency. The V2 range index was designed with numeric and time columns in mind to provide low latency range queries – though not as low as on sorted columns, but lower latency than scanning or the V1 range index.
The V2 range index has shown 5-10x improvement on numeric and time columns in various use cases. The index is available in 0.9. , but not enabled by default, and will become the default in 0.10.0. To use it in 0.9. , add “rangeIndexVersion”:2 to your tableIndexConfig.
V4 Raw Index
Raw forward indexes store data like text and JSON. Pinot’s raw indexes have been historically very good at storing fixed width data (e.g. numbers) or variable length data (strings) with narrow distributions of lengths because a fixed number of documents are assigned to each chunk of the index. This is suboptimal when the distribution of lengths has a fat tail because it leads to an overestimation of the chunk size, which is done based on the longest value in the segment. This can lead to high memory consumption or a low number of documents in each chunk, which increases decompression overhead. The V4 raw index changes this by assigning a variable number of documents to each chunk but using a fixed chunk size in bytes, which leads to better packing of documents into chunks, and reduces worst case memory consumption. It is available in 0.9.* but requires field level configuration to use:
"fieldConfigList": [{"encodingType": "RAW", "name": "field", "properties": {"rawIndexWriterVersion": "4"}}]Code language: JavaScript (javascript)LZ4 default compression
Historically, Pinot only used Snappy compression for raw indexes, but in 2021 LinkedIn added support for numerous compression algorithms. We found that LZ4 was generally twice as fast to decompress as SNAPPY, with comparable compression speed and ratio. The V4 raw index can use LZ4 fast decompression, but all raw indexes will use LZ4 safe compression from 0.10.0 onwards.
Numerous profiling-informed performance improvements
We have made numerous performance improvements based on profiling customer setups for new use cases during onboarding. Some of these are significant and should be noticeable upon upgrading to 0.9.*.
Segment Merge Roll-up Task and more
Presenter: Subbu Subramanian, Sr Staff Engineer at LinkedIn and Apache Pinot PMC
Segment merge addresses the problem of having many small segments being added regularly to a table. These can be combined to form a few big segments, thus improving both query performance as well as storage utilization. During merge, you can also enable roll-up of data so that recent segments have fine granularity of data while older segments have coarser granularity, thus saving space even further. Each column can be configured to be aggregated independently in the rolled up segments, as illustrated below:

Watch video on Segment Merge and Roll-Up Task: Segment Merge and Roll-up Task
Broker level segment pruning for time columns
To improve query performance we have added time-based segment pruning at the broker level. This is a configurable feature on the pinot broker and enables the broker to prune the segments that do not fall under the time filter specified in the query.
Explain Plan
We had added the EXPLAIN command that outputs the query plan without executing the query so you can get an idea of which operators will be invoked, should the query be executed.
LZ4 and ZSTD compression support for raw index
We added more compression types to support raw index.
Query cpu time measurements
Executing a query uses CPU over many threads. We have added a mechanism to measure how many thread-cpu-nanoseconds are used in executing a query. The measurements gathered are being used at LinkedIn to help provision the right amount of hardware for a use case. These measurements are at server level and are aggregated at the broker and logged with the query log. These logs also help identify expensive queries that may cause other queries to be slower.
Server level segment pruning for IN clause using min-max statistics and bloom filters
For queries that have IN clause, we have added segment pruning mechanisms that will speed up the query execution. The mechanisms use metadata (min-max values) and bloom filters to prune out segments.
Compatibility testing framework
Pinot is a distributed service, and all parts of it cannot be upgraded at the same time. Therefore, a period may exist where, for example, the old version of a server needs to interact with the new version of broker, while queries continue to be served. Any incompatibility during such an upgrade will cause the service to be down. Sometimes, a release has to be rolled back due to some reason.
We now have a compatibility regression suite that you can configure with your tables and sample data, to ensure that compatibility is not broken when you upgrade (or rollback)
Broker to server netty TLS channel authorization
We add a TLS authorization for broker to server the net using netty TLS.
Declarative Access control for REST endpoints (for Contributors)
Controller REST endpoints can now be coded up with declarative access control primitives. This feature is useful for pinot developers who add new APIs to the controller. It obviates the need for developers to add ACL mechanisms to each call – be it at cluster or table level permissions that need to be granted for that call.
Geospatial Support, Partial Upsert, Complex-type Support, Lookup UDF JOIN
Presenter: Yupeng Fu – Staff Software Engineer at Uber Inc, Apache Pinot Committer
Over the past year, we have seen significantly increased interest in Pinot and at Uber, and along the way that motivated us to make several contributions on different fronts.
Geospatial Support
Uber by nature is highly relevant to the geo locations. Our mission is to put the entire world into motion. So if you open up your UberEats app, if you use UberEats, the one interesting feature is to show the popular orders around you.

So this is a very good example of how we use the geo information inside Pinot. It’s pretty straightforward from the query perspective that you can use a standard geospatial query which starts with ST_ and to select orders within a given distance from a particular point. What’s cool here is that we not only introduce this geo data type in functions, but also contribute a geo index, which can significantly improve the performance. As you can see in the diagram below, if you want to retrieve orders near the San Francisco area with the geo index, you’re able to only retrieve relevant order information within the hexagon nearby, but not necessarily scan all the orders across the entire world.

Watch Geospatial Support in Apache Pinot
Partial Upsert
Last year we contributed Upsert to Pinot and it became very popular both inside and outside Uber. This year we made several improvements over Upsert. For example, we allow the direct segment push to the real time Upsert table while making interventions over that. Another interesting improvement is partial upsert. This has become very convenient for the table owners to ingest up to date information because it allows you to only specify the columns that are updated and keep the others ignored. For example, in the Uber case, we can have the events represent some justification adjustment to the rideshare, for example, the tips. Then for these updates, we can simply ignore the other columns. What’s more, we provided multiple in-built strategies to cover the most common partial upsert logic. And we’re also working on a groovy based script that can give you more power to customize logic of upsert logic.


Complex Type Support
- Handling of arrays/structs during ingestion
- Alternative to JSON index, e.g. group by nested field
Another interesting contribution we made this year is to bridge the Pinot data model and the complex data model such as in AVRO or JSON to handle data types like Array and Structure in the ingestion. In addition to the JSON Index support, this one is to cover some scenarios that people need to have a native data format for some fields. For example, if you want to group by some nested fields, this gives you a way to extract this field out as part of ingestion and saves a lot of effort for people from building a streaming processing pipeline for data ETL. Inside of Uber this is pretty popular for the table owners because of the tremendous work from their side. You can read more about this feature on how we manipulate the complex transformation in the documentation.
Pinot Docs on Complex Data Types: https://docs.pinot.apache.org/basics/data-import/complex-type
Lookup UDF Join
Last but not the least, we also made a good contribution on the lookup join. This is another popular demand we have seen at Uber that people want to decorate some existing Pinot tables with additional fields from another dimension table. For example, in this query people want to retrieve the analysis of the restaurant orders, but because the order information is denormalized, each event only carries the restaurant ID. To make the results readable, the lookup join can allow you to decorate results with additional information. In this example, we decorate the name and country of the restaurants, and we can calculate the revenue for the open restaurant for any given day. Today the lookup join only applies to a small dimensional table, and we do this by replicating this dimension table to all the servers to enable the local look up. We have seen more different types of joins, and the join is one of the active development areas that we’re looking forward to more contributions for the upcoming year.

Pinot Docs on Lookup UDF Join: https://docs.pinot.apache.org/users/user-guide-query/lookup-udf-join
Amazon Kinesis Connector
Presenter: Neha Pawar, Founding Engineer at StarTree and Apache Pinot PMC and Committer
We added a new real-time stream plugin to Pinot this year, for Amazon Kinesis. Before this, people who were using Kinesis would have to set up MSK in their cluster and set up a Kinesis-Kafka connector pipeline to transfer their events from the Kinesis to Kafka. This resulted in additional operations to manage the connector and additional costs for operating Kafka. Now, with the Kinesis connector, they can natively ingest events from Kinesis directly.
How to use Kinesis stream
In your streamConfigs, in the tableConfig, specify
- Stream type as kinesis
- Consumer type as lowlevel
- Topic name
- Consumer factory class as org.apache.pinot.plugin.stream.kinesis.KinesisConsumerFactory
- Kinesis specific properties like the region, access key, secret key. You can use Default 1. CredentialsProvider or Anonymous CredentialsProvider instead of BasicCredentialsProvider too.
- Offset criteria – similar to offset criteria in Kafka, which is latest/earliest, in Kinesis, we provide the shardIteratorType. The supported values here are latest, at_sequence_number, after_sequence_number.

While Kinesis was pretty similar to Kafka, there were some key differences because of which we had to refactor and rethink how our real time stream ingestion driver works.
Key differences in stream behavior
- Splitting/merging of shards In Kafka, partitions can only just keep increasing. In Kinesis, we have the concept of splitting and merging shards. For example, if you start with shard-0, and then see an increase in ingestion rate, you could split shard-0 to shard-1 and shard-2, making shard-0 reach the end of life. And similarly, if you merge shard-1 and shard-2 because your ingestion rate is now lower again, they will reach their end of life and we’ll have shard-3 . For this, we added support to handle shards/partitions retiring in a stream.
- Sequence of shards Due to the splitting and merging behavior of shards, there’s a natural sequence that the shards follow. For this, we added support to only read child shards after parent shards have been read, and follow the natural order.
Kinesis Connector in Apache Pinot Docs: https://docs.pinot.apache.org/basics/data-import/pinot-stream-ingestion/amazon-kinesis
Native Text Indices and LIKE Operator, Dictionary Based Query Execution Plan for DISTINCT
Presented: Atri Sharma, Distinguished Engineer at Securonix and Apache Pinot Committer
Support Pinot native FST and text search library, optimized for Pinot specific use cases
Pinot is now moving towards native text indices using an in-house text indexing and search library. In status quo, we build sidecar Lucene indices and accept Lucene syntax text queries and pass them through to the index.
This limits our ability since Lucene is a generic search engine and builds its own inverted index. Pinot, like other databases, needs to support a subset of query types and not everything that a generic search engine does.
Native FST and text search library allows Pinot to control its destiny and have specific optimizations, such as more elaborate term offsets allowing better performance and specific optimizations for prefix and suffix queries and streaming FST, allowing text search to happen on data as it streams (and not wait for flush). This will be an industry first.
Initial tests on native FST vs Lucene FST indices show 20-50% performance improvement
Support LIKE operator (utilizing FST index) to be more SQL Standard compliant
The LIKE operator, which is defined with SQL standard was recently introduced in Pinot as well, and it uses the FST indexes available and it’ll soon use the Lucene text index as well. So the idea here is to eventually move to a native text index model, which is SQL standards compliant. Currently, we have LIKE operator committed to master.
Native FST Based Index vs Lucene FST Based Index for LIKE Operator performance comparison shows 25-50% performance improvement for native FST.
And there is more work coming in this direction right now.
Usable by setting type = native for FST index
Dictionary Based Query Execution Plan for DISTINCT
DISTINCT queries were unable to use dictionary based query plans earlier, which led to a lost opportunity in terms of optimizations in query execution. Now, DISTINCT operators can use a dictionary based query plan when the query has certain constraints.
The query planner has added intelligence to allow the query plan to be built the correct way and no inputs or changes from the user are required.
Performance tests show a performance improvement of around 40%.
Trino Pinot Connector: Aggregation Pushdown and Passthrough Broker Queries
Presenter: Elon Azoulay, Software Engineer at CloudKitchens and Apache Pinot Contributor
We use the Trino / Pinot connector heavily in production at CloudKitchens. This is just a basic overview. There are two modes, one where if there are no aggregations it will directly query the server. We contributed a pull request to use GRPC streaming for direct server queries. We use the grpc server endpoint by default in production and it works perfectly. The other mode is to submit a broker query, which happens if you do aggregation push down or a pass through query. The query will go to the broker instead of streaming from the servers. Pushing down aggregation can turn a query that takes seconds or even minutes down to milliseconds or seconds. And we recently landed changes to support Pinot 8 and the connector. Judging from the user feedback on slack it also works for Pinot versions greater than 8, but we’re working on updating it to be compatible with 9 and 10.

Trino Pinot Connector: Aggregation Pushdown
Chasing the light: Aggregation pushdown
Issue single Pinot broker request Best-effort push down for aggregations like count/sum/min/max/distinct/approximate_distinct, etc 10~100x latency improvementTrino Pinot Connector2Copy
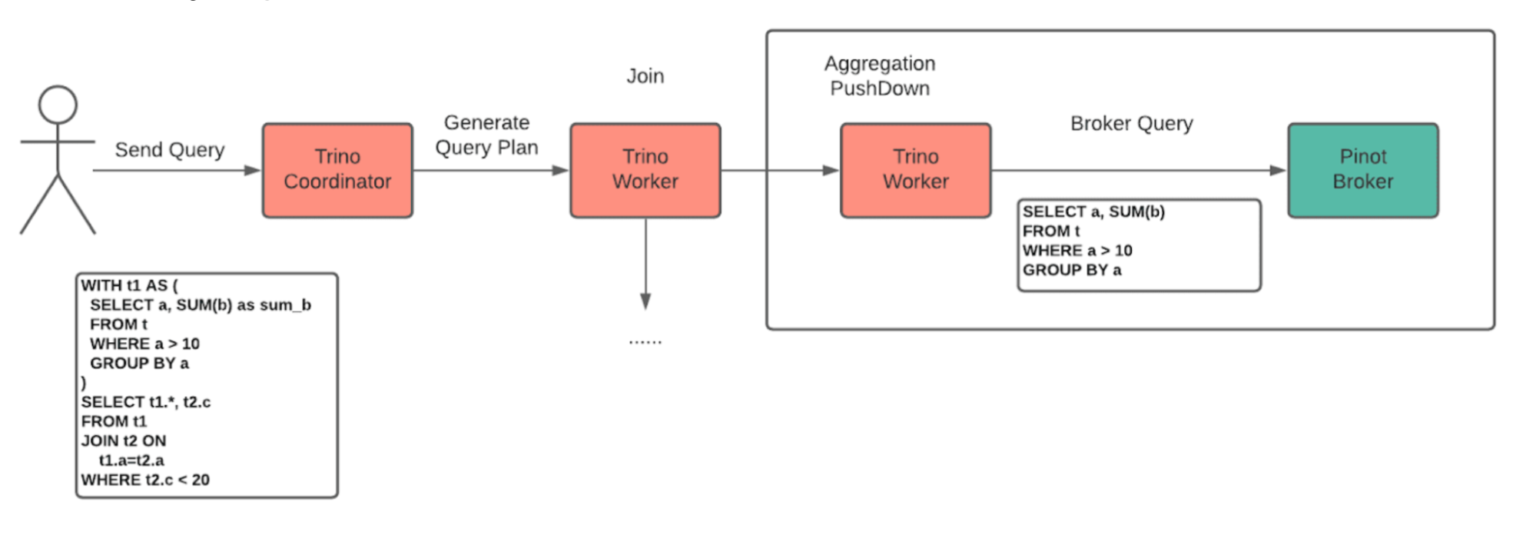
Aggregation pushdown was the major change we contributed this year. The connector now supports complex group by and other expressions in addition to simple column references. The connector will convert the query into a broker request. Instead of aggregating in Trino, the engine will push the aggregation to the broker, which was for us a major win in terms of performance.
Passthrough Broker Queries
The syntax looks a little strange but this is the way you can push an entire query into Pinot, including udf’s and other Pinot specific sql. Note that Trino lowercases the entire passthrough query, as it is considered an identifier. According to the sql standard, identifiers will be lowercase.
We did add some features to automatically uppercase commonly used parameters like time units in the date time transform functions. This allows us to support dateTimeConvert and dateTrunc.
If you need to pass a mixed case constant in a filter you can put the filter clause outside the double quotes and the connector will push the filter into the broker request.
The main contribution we are working on now is Pinot insert. We use the segment mapper Pinot api from the Pinot code. We will be updating the pull request as it evolves and work with the community to make sure everyone can use it.

Apache Pinot – Vision and Roadmap
Presenter: Kishore Gopalakrishna
As we see more adoptions of Pinot, we see a growing need for people wanting to do more things with and on top of Pinot. Luckily, Pinot has a flexible architecture and, fortunately, we got some of the architecture right in the beginning. This helped us make all plugable capabilities and make them extensible. That is aligned with our vision…to open up these restrictions so that it helps us achieve more coverage while not compromising on the speed.
Initially, Pinot was made with a strong idea of storage and compute being tightly coupled, and this was for achieving very low latency at high throughput. Now, we will be working on decoupling this tight integration.There is a lot of work going on in the SPI already, to make sure that we have a very strong spec laid out, so that the local and the remote can work independent of each other.
At the same time, you can have a table in both modes, where you can say something like, for the last seven days, I want the storage and compute to be tightly coupled (because most of the people query during that time)…and for any data that is beyond seven days or 30 days or 60 days, whatever your use case requires, you can say, I want it to go directly to S3. This allows you to get the best of both worlds, which is very good performance for the recent data. At the same time, it has very high efficiency for the old data, which is natural and the things that are happening in the cloud, with the bandwidth increasing between the storage and the remote storage, allows us to do some of these things.

We also started off the project with the assumption that once the records come in, they don’t get updated. The next thing we’re planning is to go beyond immutable records. And as part of this, we are also thinking of adding a write API, as Pinot is more towards ingestion or derived source, (point at a source, and pull the data into Pinot), so not only being able to update the data at a record level but we will also provide write APIs on top of this.

Structured data was another part of our initial design requirement. We wanted to make sure that every field has a very strong data type associated with it. This req is now evolving, as the more data comes into Kafka and other streaming sources, the data is not really structured. Some are semi-structured and deeply nested, while others are completely unstructured. Now, we want to go in the direction of semi-structured, as well. There is already progress in things such as JSON indexing and text indexing, which is kind of taking us beyond the concept of structured data. So we have semistructured and unstructured support already, but we will continue to enhance improved efficiency in how we are sorting this.
The key thing to note here is we want that concept of flexibility to be there across all these features, and one of the beautiful things about Pinot, is that every column can be either structured, semi-structured, or unstructured. And it’s not really at a table level, as it can even go at the granularity of a column level, and that’s a very powerful feature. It lets you build amazing applications some data (that is not accessed often), can be in an semi-structured model or even in an unstructured column, but as soon as you need some very good performance on that, you can create a direct column from that semi-structured or unstructured data, and the performance will be really good. Having that capability is really amazing and lets you use one system as your workload requirements change instead of continuously moving from one system to another.

We always restricted Pinot to support only a single table query. However, one of the most requested features for Pinot is going beyond a single table.
A lot of people achieve this through Pinot + Presto or Trino integrations (Spark connector is coming). While that is really good, there are still a lot of performance improvements that we can do by supporting joints natively within Pinot. This is going to be a big change given that it’s not trivial to go from a single table to a multi-table but, given the architecture and the SPI we have in Pinot, this is something that is visible and is another thing that we will be focusing on as one of the big things in 2022.

Please let us know if there is anything else that we are missing here in terms of the big topics. We will look into it.
Below are some of the requests we received from the community. We also have a Polly link that we are asking our users to upvote or add ideas about things you’d like to see or you would like to contribute to as well. We encourage contributions. We have a slack channel if you’d like to discuss or brainstorm ideas with us.
Vote for 2022 features, integrations, and more by the end of the year in our community Polly: https://poll.ly/#/Pvy1rpp2
Join us on the Pinot Slack https://communityinviter.com/apps/apache-pinot/apache-pinot