
We are pleased to announce that Apache Pinot has graduated and is now a top-level Apache Software Foundation (ASF) project!
For those of you who are unfamiliar: Graduation is when a “podling” becomes a top-level Apache project (or a subproject under an existing Apache project). It means that the project has met all the major criteria as described by ASF graduation guidelines.
But most importantly, it speaks to the strength of our community.
Community is the heart of any open source project. That’s why ASF makes one of their biggest criteria for graduation the development of an open and diverse community. History has shown that such communities are more robust and more productive, and that truly is the case when it comes to Apache Pinot.
For us, having such a robust and committed community has been both a cause of our success and a continuing effect of it. We have been truly honored—and a bit blown away—by the number of developers, committers, and champions who have all been a part of our project.
Our Community, by the Numbers
To give some idea of what we mean, here are some of our top contributors along with the word cloud of all contributors, as well as some stats showing just how active and rapidly growing our community has been:

Do you see the graduation hat? Read more about our contributors here!
Community Metrics & Growth

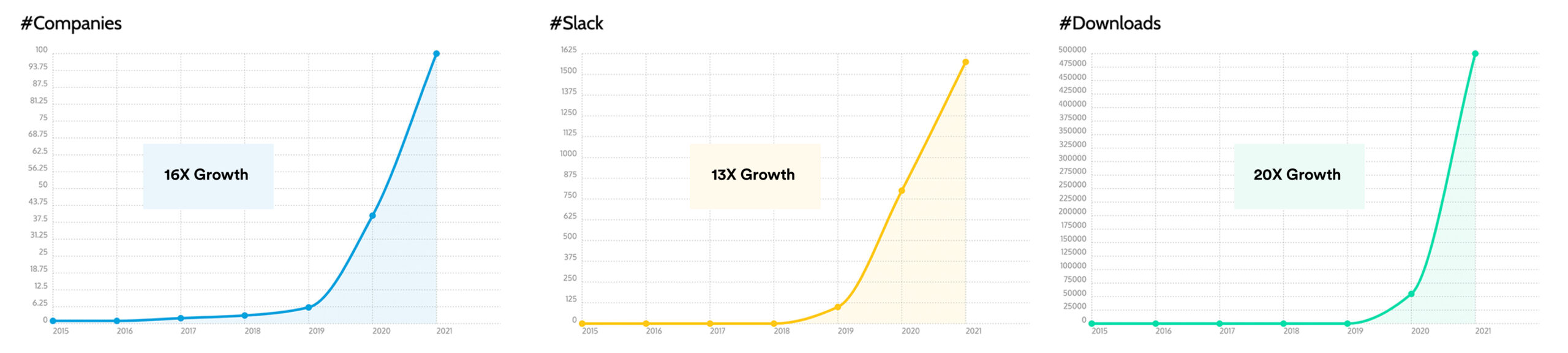
In the last two years, we have seen the number of companies getting involved with Apache Pinot increase from 6 to 100+, a 13x increase in the number of slack members, and a 20x increase in the number of docker image downloads.
Thank you to all the incredible contributors who helped get us to this milestone!
If you, too, would like to join our community, you can join our Slack channel, or visit the Apache Pinot community web page.
A History to Be Proud Of
Pinot originally started as a specific solution at LinkedIn around six years ago (2015). At the time, we had never dreamed it would become a standalone project. But as people who had worked on Pinot at LinkedIn went to work elsewhere, they supported the idea of bringing Pinot to the wider world. It quickly became clear that, though there were plenty of open source solutions for data ingestion and querying, Pinot was helping companies (such as Amazon-Eero, Doordash, Factual/FourSquare, LinkedIn, Stripe, Uber, Walmart, Weibo, 7-Eleven, and WePay) much more specifically with their use cases, especially when it came to user-facing analytics.
Pinot’s growth could have easily stopped there, however, if not for its entering incubation in 2019. This move brought the product into new industries and brought on new features. Pinot soon became a tool that could work for all industries and companies of all sizes.

We have been working across three layers (highlighted are in the works) to make Pinot more valuable to our users:
- Expanding both mutable and immutable ingestion data sources has always been high on the list. These include Apache Pinot integration with Amazon Kinesis, Apache Pulsar, and Debezium for change data capture.
- At the Apache Pinot layer, we have been making investments to improve speed and efficiency by adding support for additional indexes such as Geo, JSON as well as bringing in the new feature and query capabilities that offer tiered storage, perform various segment operations, allow nested queries and more.
- Lastly, as we see Apache Pinot getting adopted across various industries, we are adding enhancements to meet those use case requirements and make it super easy to visualize and unlock the value of data through integration with connectors such as Tableau and Looker. Most of them are already in the works to make Pinot more powerful and more versatile.
Again, it was the community that made this happen. There are, literally, thousands of GitHub and other open-source projects out there. It’s different, however, when your project has a name and community built around it. That community is truly what helped take us to the next level.
What’s Next?
If you’ve ever attended college graduation, there’s a theme you likely picked up on: A graduation is not just the end of something, but the beginning of something even bigger. It’s a chance to celebrate, but it’s also very much a time to look ahead.
The same is true of this graduation. So we thought it only appropriate to look ahead at the landscape and what’s next for Pinot. Based on user and community feedback, our roadmap is geared towards adding unique and powerful storage and query capabilities into Apache Pinot.
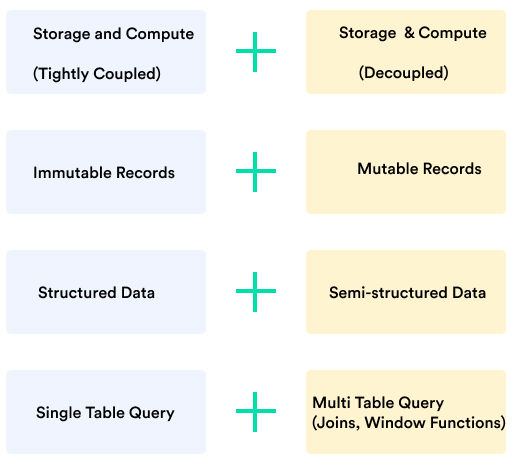
- With decoupled storage and compute capabilities, users will be able to independently scale storage and compute, providing much more efficient cluster operations and catering to numerous new use cases.
- Support for mutable data already exists and we will continue to enhance it by supporting partial upserts and enabling it for special indexes like star-tree index.
- We will add support for semi-structured data such as JSON, Struct, and other types of Nested records. This will avoid having a separate ETL process to transform a complex object before ingesting it into Apache Pinot.
- On the query side, functions such as join, window, and match-recognize will give users and applications the power to run more sophisticated queries that span multiple tables.
We fully expect that the numbers for Apache Pinot will continue to grow with time—the commits, the features, the downloads, and the people joining our Slack and attending meet-ups. That’s not because (or not just because) Pinot is a revolutionary piece of technology. It is because we have a community that sees the potential in something, and together wants to make that thing the best that it can be. We are just happy to facilitate and help make that happen.
Cheers to the community for getting us here! Can’t wait to see what we do next.
- Download page: https://pinot.apache.org/download/
- Getting started: https://docs.pinot.apache.org/getting-started
- Join our Slack channel: https://communityinviter.com/apps/apache-pinot/apache-pinot
- See our upcoming events: https://www.meetup.com/apache-pinot
- Follow us on Twitter: https://twitter.com/startreedata
- Subscribe to our YouTube channel: https://www.youtube.com/startreedata
