
Every product today is a conglomeration of thousands of services that exchange data with each other to create the best possible experience for the users. However, for businesses, there is also the need to see the bigger picture to evolve the product. This is where real-time data streams and analytics systems come in. Using these systems, businesses can make critical decisions such as User fraud detection, anomaly in the metrics, etc. without waiting for a couple of days for data.
Apache Pinot allows businesses to quickly transition to real-time analytics without compromising on latency, throughput, and infrastructure costs. In addition, Pinot features an extremely pluggable architecture. It makes extending Pinot’s compatibility for multiple third-party data providers a seamless task.
In this article, we introduce you to the Pinot Kinesis plugin. We’ll also take a look at how you can use Apache Pinot and AWS Kinesis to quickly create a robust, scalable, and cost-efficient real-time analytics system for your product.
What is Amazon Kinesis?
Amazon Kinesis is a fully-managed real-time data processing solution by AWS. It offers key capabilities to cost-effectively collect and process streaming data at any scale. Developers can ingest high throughput data such as video files, IoT signals, etc. with Kinesis. With Kinesis’ real-time capabilities, developers can react to data as it arrives which provides a better experience for the customers.
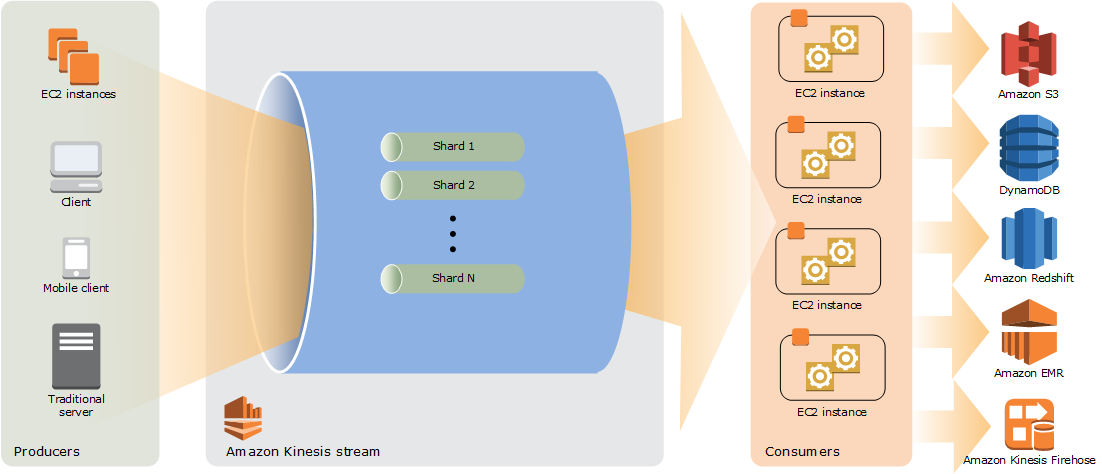
Challenges with Analyzing Real-Time Data
One of the major challenges with analyzing real-time data is running low-latency multi-dimensional queries. Real-time decision-making is extremely critical for business use cases such as Fraud Detection, Anomaly Reporters, order delivery optimizations, and more. The results should also reflect the latest state of the data and not some point in the past e.g. 1 hour ago. For example, imagine you have an online food delivery service connecting restaurants to diners. You can run a query to get the latest locations of all the drivers in a particular zip code. You can then use this information to distribute demand for orders in a more optimized way.
Don’t Worry, Apache Pinot is Here to Help
Apache Pinot comes packed with features for this use case. Pinot allows users to ingest real-time data from different data sources.
Users can run complex queries on top of the ingested data and expect a response within milliseconds thanks to Pinot’s optimized routing and pluggable indices. In addition, Pinot is extremely scalable, fault-tolerant, and provides multi-tenancy out of the box which makes it possible to use it in production-critical workflows. You can check out all the features here.
Kinesis Plugin for Pinot
Developers can implement Pinot’s Plugin interfaces, package the code, and put it in Pinot’s classpath. This allows developers to add new real-time/batch datasources, a custom distributed storage provider, or an efficient data serialization extension. Developers don’t have to compromise with existing choices or execution speed because no code changes are required in Pinot’s core.
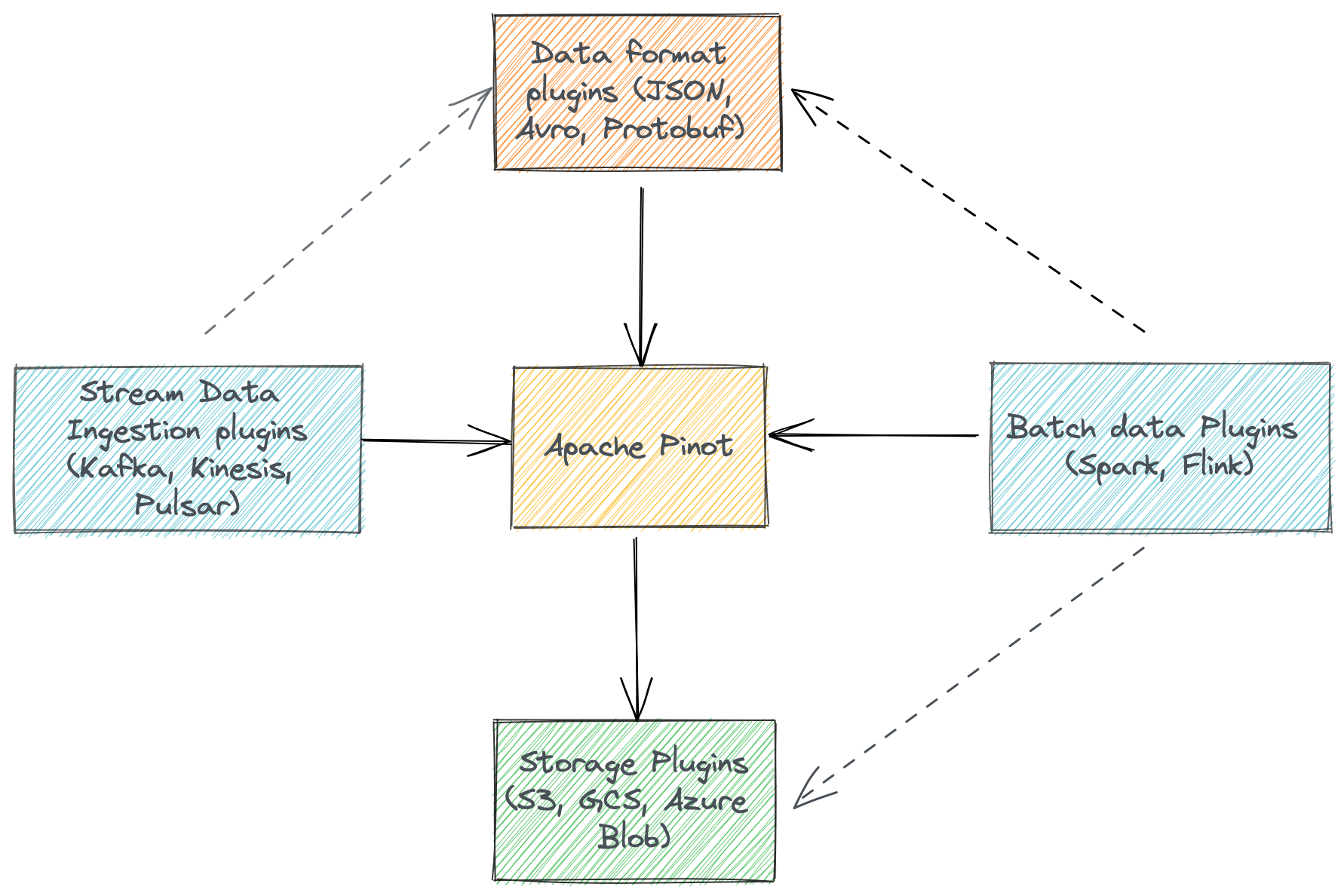
We are pleased to introduce the pinot-kinesis plugin to process data from Kinesis streams. It allows users to ingest data from Kinesis with just a few lines of configuration and zero code changes.
Let’s start with an example demonstrating how you can set up a Kinesis table in Pinot.
Analyzing Github events with Pinot
We’ll be using Amazon Kinesis to collect event data from GitHub’s public REST API. We chose GitHub events because it is a publicly available constant stream of events. It also provides us with interesting relatable insights about open source projects. Then we will use Pinot to run analytical queries on the aggregate data model that resulted from records stored in the Kinesis stream.
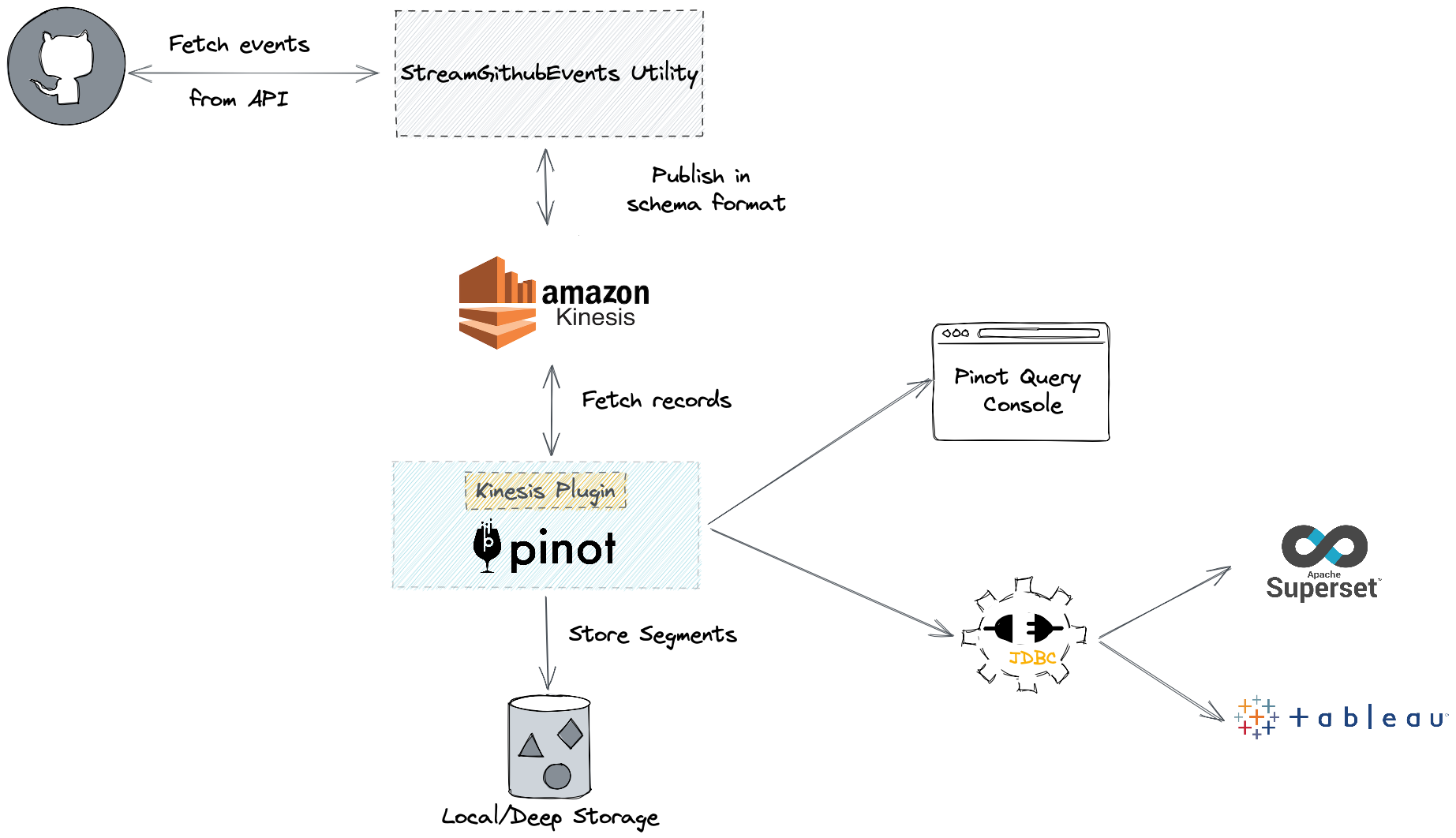
Create Stream
Let’s first create a Kinesis stream with 3 shards.
aws kinesis create-stream --stream-name pullRequestMergedEvents --shard-count 3Create Schema
We will be combining information from the PullRequests API along with the information from Commits, Reviews, and Comments API. This results in a neat table with all the necessary information in a single row.
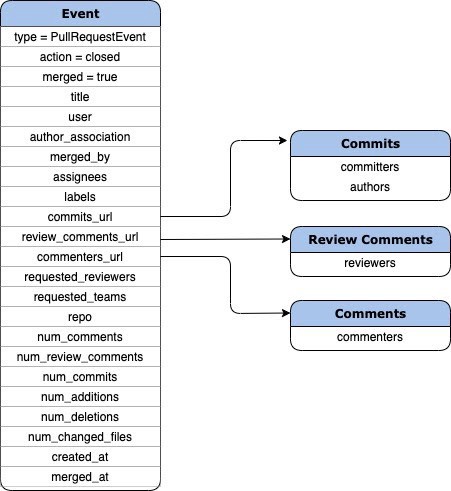
The final schema will look like this.
Create Table
Our next step is to create a table in the database. We need to create a config for our table which tells Pinot from where to consume the data, the decoder to use for parsing data, schema to be used, and other details. For our use case, we will be using the Table config provided here.
Let us understand a few key Kinesis parameters mentioned in the config:
- region – Set this value to the AWS region in which your Kinesis stream is located
- shardIteratorType – determines the initial start position of the stream. Can be one of TRIM_HORIZON, LATEST, AT_SHARD_ITERATOR, AFTER_SHARD_ITERATOR
- accessKey (optional)- the access key for your AWS account
- secretKey (optional)— the secret key for your AWS account
The Kinesis plugin in Pinot uses the AWS credentials from the machine on which it is running or from the environment variables. Users should not provide AccessKey and SecretKey as part of the config in production environments.
We can add the table config and schema to Pinot using the following command –
bin/pinot-admin.sh AddTable -tableConfigFile github_events_table_config.json -schemaFile github_events_schema.json -execPublish Data
We will be using the /events API from GitHub. We are going to collect events of type PullRequestEvent which have action = closed and merged = true. For every pull request event that we receive, we will make extra calls to fetch the commits, comments, and review comments on the pull request. The URLs to make these calls are available in the body of the original response from Github.
Since this can sound a bit tedious, we have written a small utility in Pinot to publish these events to any data sink continuously. You can use the following command to push events into the Kinesis topic (command available on latest master)
bin/pinot-admin.sh StreamGitHubEvents -personalAccessToken=XXXXX -topic pullRequestMergedEvents -sourceType kinesis -awsRegion us-east-1 -kinesisEndpoint http://localhost:4566 -schemaFile /Users/kharekartik/Documents/Developer/incubator-pinot/pinot-tools/src/main/resources/examples/stream/githubEvents/pullRequestMergedEvents_schema.jsonCode language: JavaScript (javascript)That’s it! As soon as data starts getting pushed into the Kinesis stream, it will get reflected in Pinot as well.
Querying data
We can use Pinot’s UI to run SQL queries on our data. If you are running Pinot locally, go to localhost:9000 and you should be able to run SQL from the Query Console tab.
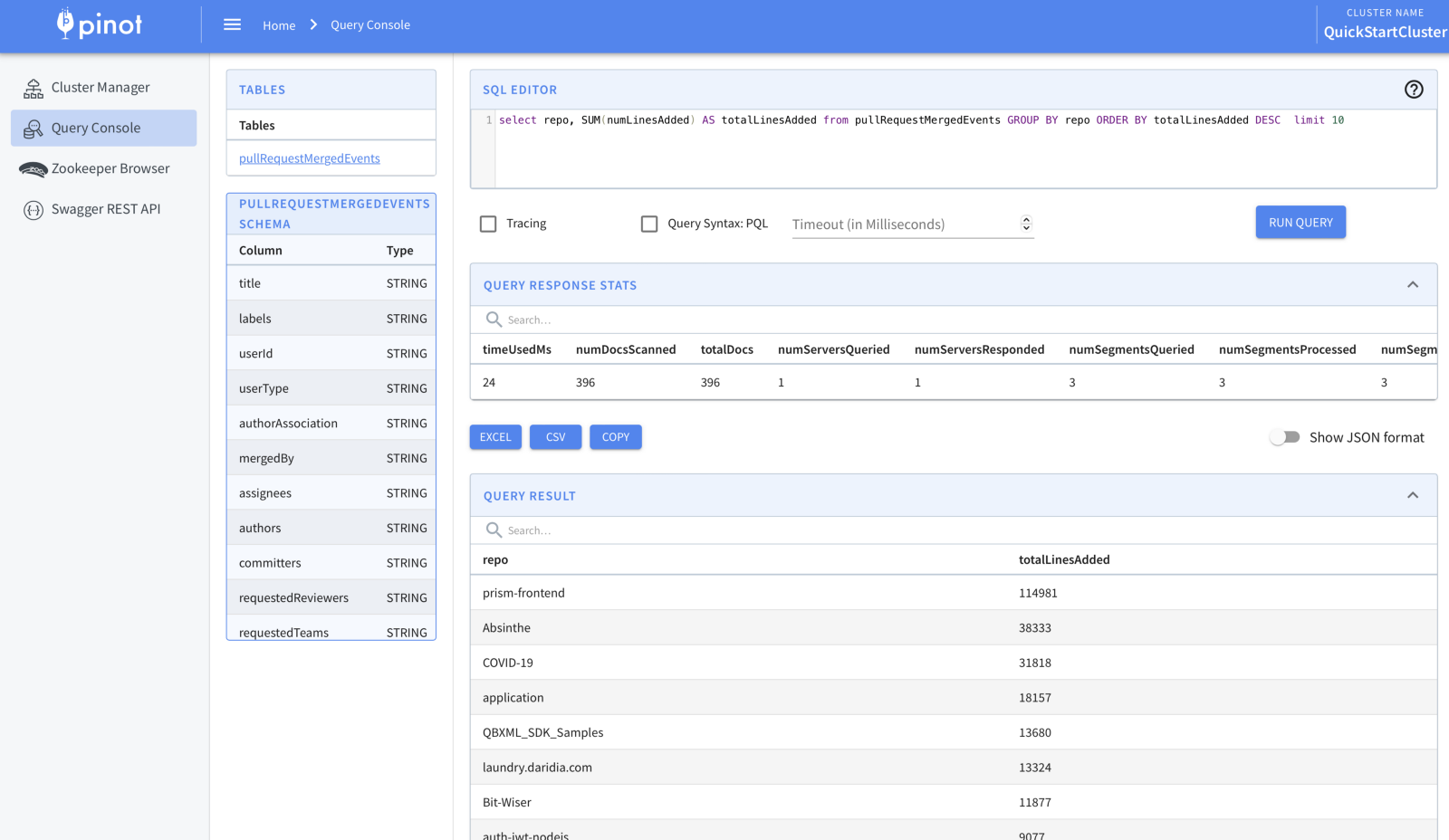
We can also use data analysis tools such as Tableau to visualize our data.
Let’s check out which repos are receiving the most number of changes with PRs.

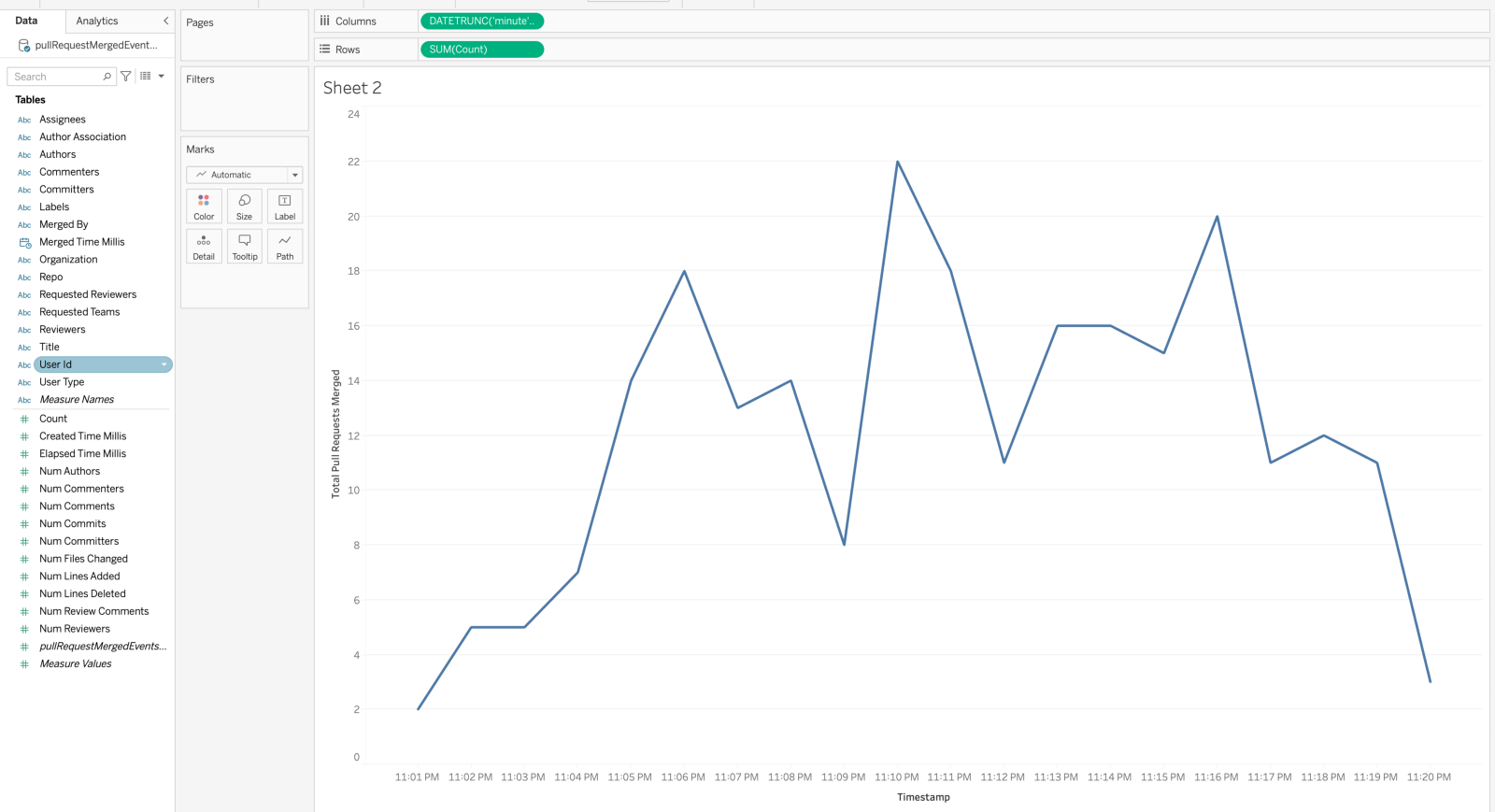
Or we can check out how many PRs are getting merged on Github every minute
Can Pinot Kinesis be used in Production Environments?
Pinot uses AWS SDK Kinesis Client to consume data from Kinesis. This allows us to have low-level control over each shard. AWS SDK also fits nicely into our pluggable model which makes it possible to have low-level control over the stream.
We designed plugin interfaces in Pinot with certain expectations in mind. e.g. for our stream datasource plugins, we expect the following to be true in the stream provider:
- The partition ids should be integers and should start from 0
- The offsets of messages in partitions should be long integers and be linearly increasing
- Existing partitions cannot be deleted or removed
- Ability to seek messages at any offset
Although Kinesis doesn’t satisfy the first 3 of these criteria, the plugin takes care of all of this. We also have handled other Kinesis quirks so there is no need for manual intervention. Let’s take a look at some of the scenarios and how Pinot tackles them.
Shard Iterator and Offset Management
You can configure the start position of the Shard iterator in the table config. By default, Pinot supports the following values:
- TRIM_HORIZON — Start consuming from the earliest available record
- LATEST — Start consuming the records published post the creation of the consumer
- AT_SEQUENCE_NUMBER — Start consuming from the first sequence number available in the shard
- AFTER_SEQUENCE_NUMBER — Start consuming after the specified sequence number
When Pinot creates tables for the first time, it uses the value as the starting position. Pinot uses its own Zookeeper to track the sequence numbers in the stream. Pinot uses AFTER_SHARD_ITERATOR for the next shard iterator after committing the first segment.
Rebalancing Shards
Kinesis Shards have a max throughput limit of 2MB per second. This creates a complication from a design standpoint. Users do a lot of repartitioning in Kinesis to balance throughput across streams. The repartitioning involves either merging two shards or splitting a shard into two. In Kafka, repartitioning a topic is not a common operation.
To handle resharding correctly, Pinot consumes data from parent shards first. This maintains the order of the published records during consumption. Amazon also advises this in their official docs.
Throughput Limits and other Exceptions
What happens when the throughput limits get breached on a shard? The AWS client will throw a ProvisionedThroughputExceededException in this case. On this exception, Pinot commits all the records fetched before the exception. Once a commit is successful, Pinot will start consuming from the next available record. Similar handling is applied on other exceptions as well such as IllegalStateException, AbortedException, etc.
Conclusion
In this article, we introduced you to the Kinesis Plugin for Apache Pinot and what changes were made in Pinot to integrate the streams. We also used Kinesis and Pinot to analyze, query, and visualize event streams ingested from GitHub. The Kinesis plugin has been available from the 0.8.0 release of Pinot.
We’re already seeing adoption from the Pinot community and the response has been great! We are working on improvements based on the community feedback.
One of our primary motivations while designing Plugin Interfaces was that the choice of implementation should not limit the functionality provided by Pinot. The Kinesis plugin adheres to these expectations. Users can continue to take advantage of our unique features such as Upserts, Real-Time Metrics Aggregations, Pluggable Indices, etc. all while leveraging the scalability of Kinesis streams.
A full end-to-end guide is available for the use case mentioned in this article. Visit Ingest GitHub API Events using Kinesis for all the steps.
To learn more about Pinot and provide feedback, become a member of our open source community by joining our Slack Channel . You can also follow @apachepinot on Twitter, subscribe to our YouTube channel, and join our Meetup Group!
About the author: Kartik Khare
Kartik is a Software Engineer III at Walmart and an Apache Pinot Committer. He has refactored documentation for better discoverability, added JDBC driver for Pinot and support for ingesting data from Apache Kinesis, Apache Pulsar, and Amazon S3. He added support for Scalar functions allowing users to register their custom java functions for a query. He also had minor contributions in JSON indexing. Connect with him on LinkedIn and Twitter!
